크로키의 스택 - 마이크로서비스
지그재그 서비스는 모놀리식 아키텍처(Monolithic Architecture)에서 마이크로서비스 아키텍처(Microservice Architecture)로 전환중에 있습니다. 이번 글에서는 그 과정을 설명하려고 합니다.
첫 서비스 구조
크로키는 2012년 중반에 첫 서비스 개발을 시작했습니다. 웹 서비스를 할 계획이 없었기 때문에 단순한 API 서버만 필요했고, 좀 더 성숙한 프레임워크(예. Rails)를 사용하는 대신 Node.js + Express 조합으로 서버를 구성하였습니다.
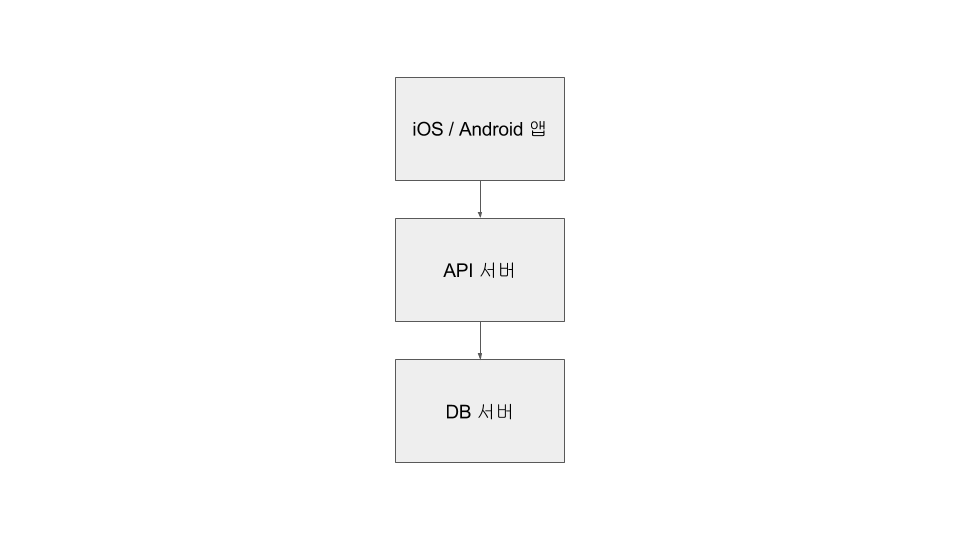
서비스가 알파 테스트 단계에 이르자 데이터를 살펴보고 간단한 조작을 할 수 있는 관리용 웹이 필요해졌습니다. 그래서 기존 서버에 관리용 API를 추가해서 관리용 웹을 만들었습니다.
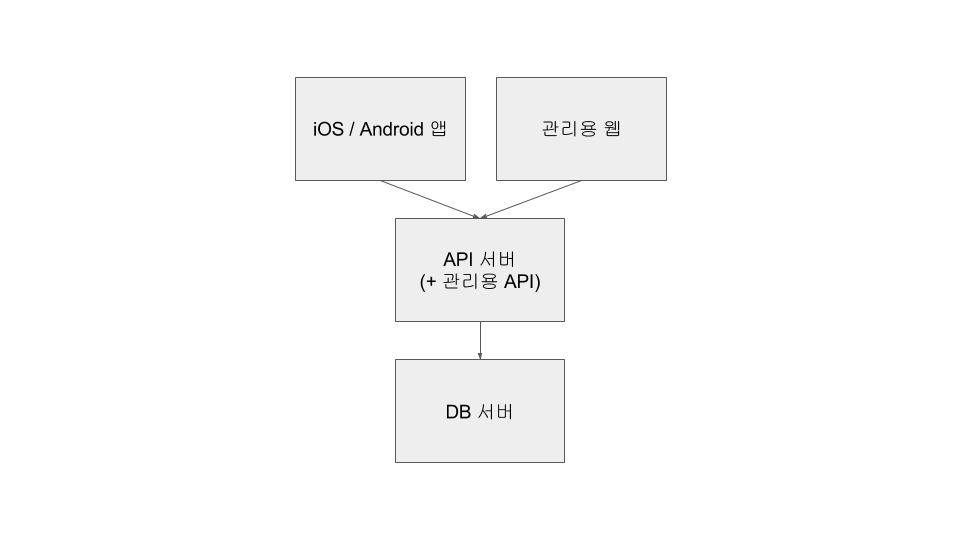
복잡해지는 구조
위의 구조는 2013년 중반에 작업한 외주 프로젝트에서도 그대로 사용했습니다. 그러나 2014년에 시작한 외주 프로젝트에서는 관리용 웹에 더 많은 기능이 필요했고, 서버 프로세스를 분리하기에 이르렀습니다. 코드상으로는 대부분의 코드를 공유하고 프로세스에 따라 라우트만 다르게 설정하는 구조였습니다.
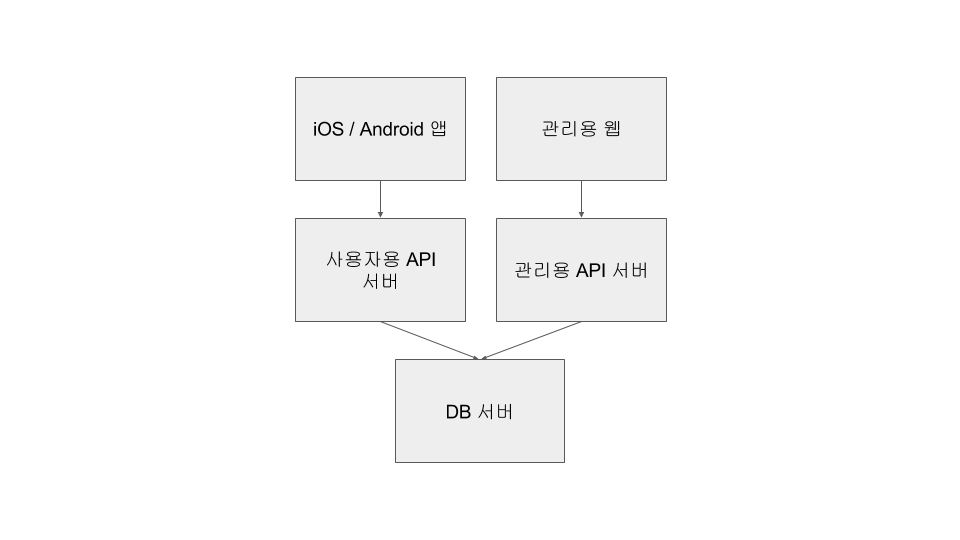
2015년 초에 지그재그 서비스 개발을 시작하였는데, 이전 프로젝트와 달리 사용자용 API는 굉장히 적은데 비해서, 관리용 API가 많아졌습니다. 거기에 업주용 웹이 필요해지면서 그에 따르는 API가 추가됐는데, 세 개의 API에 겹치는 부분이 없어서 모델 코드만 공유하고 나머지는 완전히 분리했습니다. 이 때 디렉토리는 서버와 클라이언트로 구분하지 않고, 타겟별로 구분을 하였습니다. (사용자용 API + 관리용 웹[API 서버, 웹 클라이언트] + 업주용 웹[API 서버, 웹 클라이언트] )
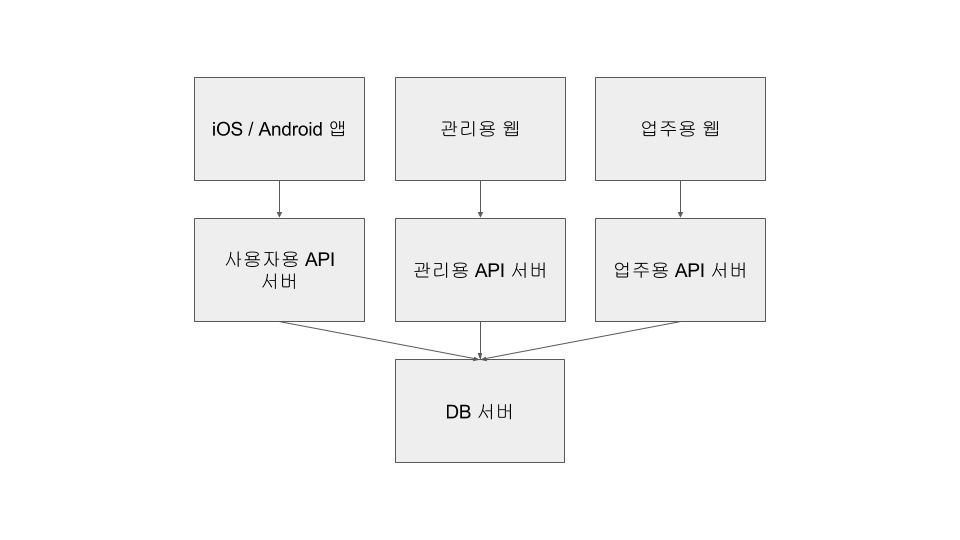
한때는 여기에 계약 관리용 웹이 별도로 존재하기도 했습니다.
마이크로서비스의 필요성
서비스가 점점 복잡해지면서 자연스럽게 마이크로서비스의 필요성이 느껴졌습니다. 개발팀이 크지 않기 떄문에 넷플릭스와 같은 진정한 의미의 마이크로서비스 까지는 아니지만, 적어도 연관된 기능을 한곳에 모아둘 필요성이 생겼습니다.
마이크로서비스로의 전환을 시작한 첫번째 직접적인 이유는 상품 검색 서버였습니다. 상품 검색에 AWS의 CloudSearch를 사용하고 있었는데, 한계를 느껴 Elasticsearch로의 전환을 생각하게 됐습니다. 그런데 상품 업로드는 관리용 서버에서 이루어지고 검색은 사용자용 API 서버에서 하기 때문에, 이를 한군데 모으면 변경하기 쉬워진다고 판단했습니다.
두번째는 로그관리였습니다. 로그를 MySQL 데이터베이스에 쌓고 있는데, Logstash, Apache Flume 같은 다른 시스템으로 전환을 하고 싶었습니다. 그러려면 로그를 추가하고, 사용하는 코드를 한군데로 모아야겠다고 생각했습니다. (하지만 로그 시스템은 여전히 못 바꾸고 있습니다;;)
마이크로서비스로의 전환 과정
2016년 8월에 전환 작업을 시작해서, 상품 서비스, 쇼핑몰 서비스, 사용자 서비스, 상품 검색 서비스 순으로 코드 분리를 시작합니다. 모든 기능을 한번에 이동하기 보다는 새로 추가되는 기능 위주로 조금씩 작업했습니다.
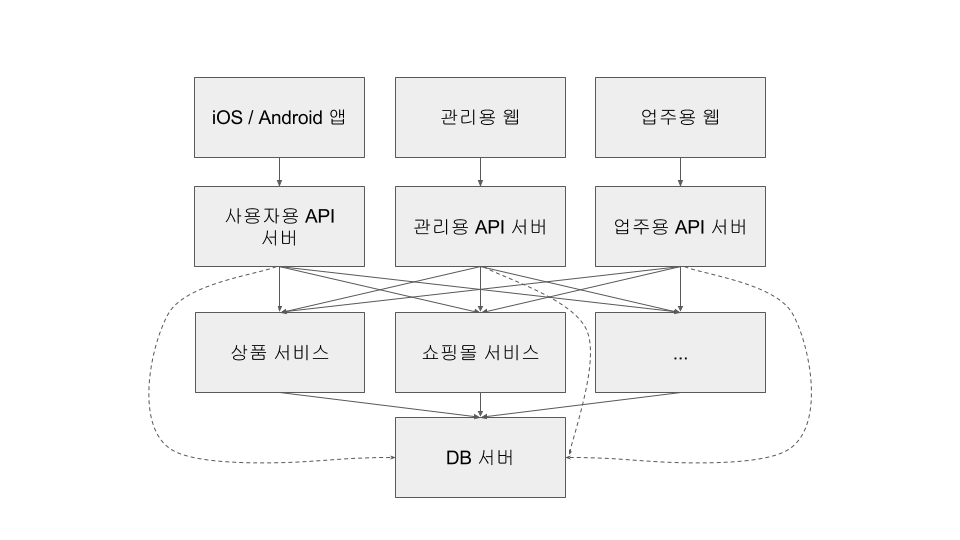
2017년 초에 새로 생긴 서비스에 대해서는 DB 서버도 분리(별도 RDS 인스턴스)했고, 8월에는 기존 데이테베이스도 거의 분리했습니다.
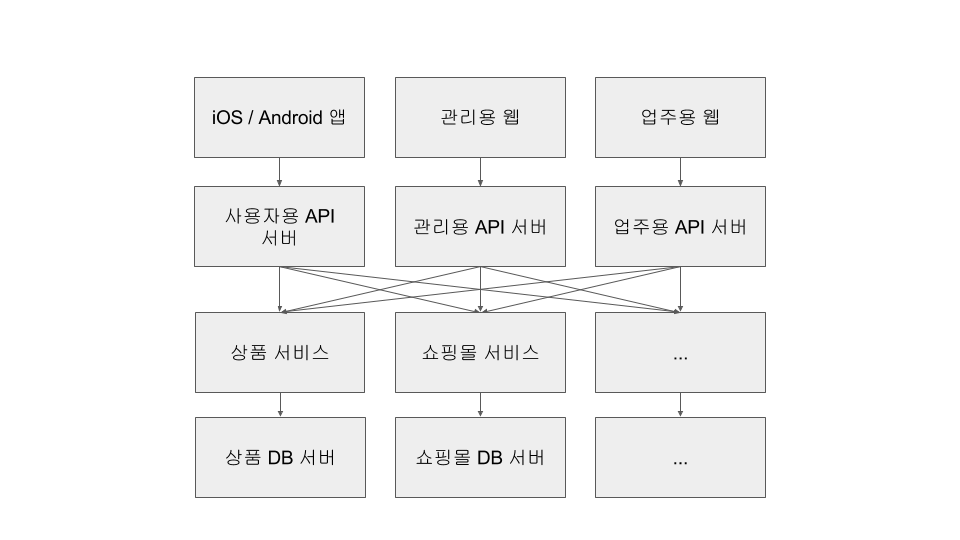
현재의 상태
전환을 시작한지 1년이 넘었지만 아직도 모든 코드와 데이터가 분리되지 않았습니다. 특히 주기적으로 실행하는 몇몇 작업은 여러 서비스의 데이터를 많이 참조해야 해서 마이크로서비스를 거치지 않고 데이터베이스에 직접 접근하고 있습니다.
그래도 마이크로서비스를 사용할 수 있는 구조가 잡힌 덕분에 최근에 작업하고 있는 BM 관련 기능은 별도의 마이크로서비스로 만들면서, 기존 서비스와 다르게 DynamoDB와 Lambda를 사용하도록 작업을 할 수 있었습니다.
현재의 구성을 용어로 표현하자면 프론트엔드를 위한 백엔드(backend for frontend, BFF) 패턴이라고 할 수 있을 것 같습니다. 이는 의도한 것이 아닌 마이크로서비스로의 전환 과정에서 자연스럽게 만들어졌습니다. 마이크로서비스를 직접 클라이언트에 노출하는 구성에 대해서도 생각해본 적이 있지만(예를 들어 상품 검색 기능), 여러 가지 이유로 적용하지는 않았습니다.
서비스간의 통신은 Apache Thrift를 사용하고 있습니다. 일반적으로 사용하는 REST를 사용하지 않은 이유는 다른 포스팅에서 다룰 생각입니다. 몇몇 상황에서는 비동기 이벤트의 필요성을 느껴 메시지 큐를 도입할 예정입니다.
모든 코드가 한 저장소에 존재하고 있고 배포는 따로 따로 할 수 있지만 실질적인 구현은 여러 마이크로서비스를 동시에 수정하는 경우가 많습니다. 현재는 진정으로 독립된 서비스라기 보다는 에러가 다른 서비스로 전파되는 것을 막고 원인을 찾을 때 범위를 좁히려는 목적이 강하다고 할 수 있습니다. 모든 서비스가 하나의 AWS 계정의 같은 VPC에 배포되고 있지만, 서비스별로 다른 계정을 만드는 것도 생각해보고 있습니다.
개별 서비스의 유닛 테스트는 잘 이루어지고 있지만, 서비스 단위를 넘어서는 통합 테스트는 아직 개개인의 경험에 의존하고 있습니다. 모니터링과 로그 수집도 더 발전할 여지가 많이 있습니다.
마무리하며
많은 곳에서 나오는 얘기이지만 서비스를 개발할 때 처음부터 마이크로서비스로 시작하는 것은 바보같은 일이라고 생각합니다. 어느 정도 기능이 갖춰지고 규모가 커진 이후에 고려해도 늦지 않습니다.
물론 한번 모놀리식으로 된 서비스를 마이크로서비스로 분리하는 것이 쉽지는 않습니다. 저희도 옮기면서 몇가지 실수로 데이터 손실이 발생하기도 했습니다.
하지만 아무도 사용하지 않는 좋은 구조의 서비스를 만드느니 어설프더라고 사용자가 원하는 서비스를 만드는 것이 더 중요합니다. 나중에라도 충분히 마이크로서비스로 전환하면서 기술 부채를 청산할 수 있습니다.
저희의 경험이 도움이 되셨으면 합니다.