BotKit을 이용한 슬랙 봇 만들기
27 Apr 2019
크로키닷컴을 시작하고 비교적 초기부터 ChatOps를 해보고 싶었습니다. GitHub의 글을 보고 도입하고 싶다는 생각이 들었던 거로 기억합니다. 당연하게 Hubot을 이용해 채팅봇을 설정했습니다.
초기에는 HipChat에 Hubot을 붙였고, 2014년 중반 Slack으로 전환했습니다. 봇을 활용하려는 시도는 여러 번 했지만 대부분 장난 수준을 벗어나지 못했고(예. 점심 메뉴 보여주고 임의로 고르기), 그나마 조금 복잡했던 것이 Box, Dropbox, Evernote에서 변경된 내용을 인식해 특정 채널에 알려주는 기능이었습니다.
그렇게 방치하다가 2019년에 들어와 개발팀 인원도 늘어나서 다시 한번 제대로 채팅봇을 만들자는 얘기가 나왔습니다. 이전에 작업해서 익숙한 Hubot을 다시 사용할까 했는데 아무래도 소스 기반이 CoffeeScript인게 마음에 걸렸습니다. 여러 가지를 찾아보다가 Botkit을 사용하기로 결정했습니다.
이번 글에서는 Botkit을 이용해 슬랙 봇을 만드는 방법을 설명합니다.
슬랙 앱 생성
Hubot은 슬랙 앱이 있어서 설정이 편했는데, Botkit은 슬랙 앱을 만들어야 합니다.
Botkit은 AI 봇을 만들어 여러 업체에 제공하기 위한 솔루션인 듯 여러 팀을 다룰 수 있도록 구성되어 있고, Botkit 슬랙 앱 설정 문서도 내용이 많습니다. 하지만 내부적으로 사용하는 용도로는 그렇게까지 필요하지 않습니다.
우선 Your Apps에 가서 새 앱 생성을 합니다.
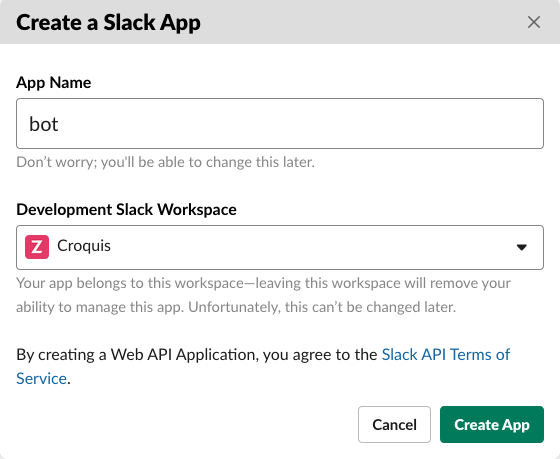
그리고 Bot Users 메뉴에서 Bot User를 추가합니다.
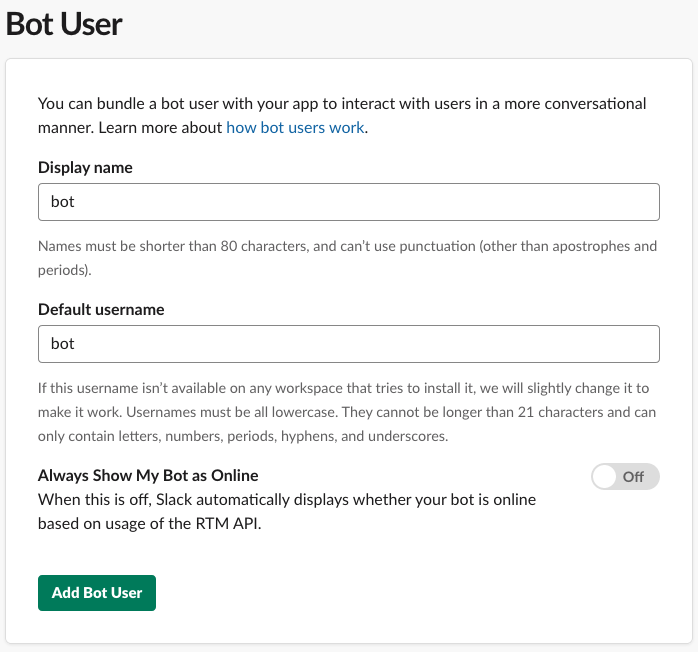
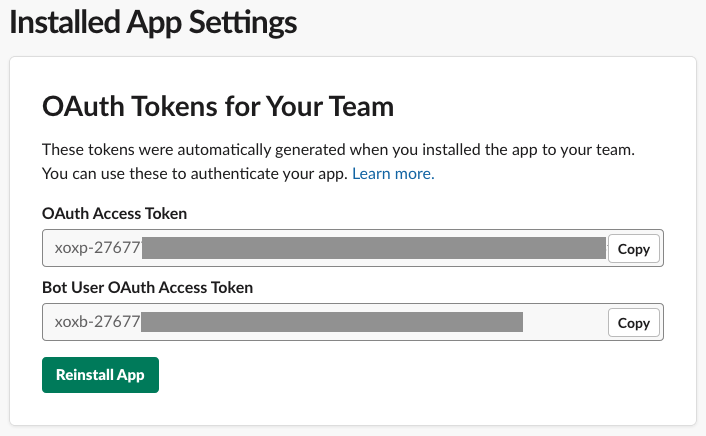
마지막으로 Install App에서 ‘Install App to Workspace’를 누르고 Authorize를 선택하면 Bot User Access Token을 얻을 수 있습니다.
Bot 만들기
Botkit Starter Kit for Slack Bots가 있지만, 이 역시 저희 용도에는 너무 복잡해서 처음부터 만들기로 했습니다.
필요한 패키지는 botkit, dotenv 뿐입니다. 그리고 TypeScript로 만들기 위해 typescript와 ts-node를 추가합니다.
package.json
{
"name": "bot",
"scripts": {
"start": "ts-node app.ts"
},
"dependencies": {
"botkit": "^0.7.4",
"dotenv": "^7.0.0",
"ts-node": "^8.0.3",
"typescript": "^3.4.3"
},
"devDependencies": {
"@types/dotenv": "^6.1.1"
}
}Access Token은 소스 관리가 되지 않는 .env 파일에 기록합니다.
.env
SLACK_BOT_TOKEN=xoxb-276777......TypeScript 컴파일 설정도 만들어줍니다.
tsconfig.json
{
"compilerOptions": {
"noImplicitAny": true,
"noImplicitThis": true,
"strictNullChecks": true,
"target": "es2017",
"module": "CommonJS",
"moduleResolution": "node",
"esModuleInterop": true,
"lib": [
"es2017",
"dom",
"esnext.asynciterable"
]
}
}마지막으로 다음과 같이 봇 코드를 작성합니다.
app.ts
import Botkit from 'botkit';
import dotenv from 'dotenv';
dotenv.config();
const controller = Botkit.slackbot({
});
controller.startTicking();
const bot = controller.spawn({ token: process.env.SLACK_BOT_TOKEN || '' });
bot.startRTM((error) => {
if (error) {
console.log('구동에 실패했습니다.');
} else {
bot.say({ text: '봇이 배포되었습니다! 😄', channel: 'Cxxxxx' });
}
});npm start를 하면 봇이 구동되고 지정한 채널에 메시지가 표시됩니다.
봇 스킬 추가
봇 동작을 기술할 스크립트는 Botkit Starter Kit에 맞춰 스킬이라고 부르기로 했습니다.
스킬 추가는 파일을 추가하기만 하면 되는 구조로 작성했습니다.
skill/index.ts
import { SlackController } from 'botkit';
import fs from 'fs';
export const loadSkills = (controller: SlackController) => {
fs.readdirSync(__dirname).forEach((filename) => {
if (filename !== 'index.ts' && !filename.includes('.disabled.')) {
require('./' + filename).default(controller);
}
});
};app.ts
...
import { loadSkills } from './skill';
...
loadSkills(controller);다음은 Botkit Starter Kit for Slack Bots에서 가져온 스킬 샘플입니다. 봇에게 color나 question이라는 단어를 포함해 1:1 메시지(direct_message)를 보내거나 언급하면 동작합니다.
skill/sample-conversation.ts
// copied from https://github.com/howdyai/botkit-starter-slack/blob/master/skills/sample_conversations.js
import { SlackController } from 'botkit';
export default (controller: SlackController) => {
controller.hears(['color'], ['direct_message', 'direct_mention'], (bot, message) => {
bot.startConversation(message, (error, convo) => {
convo.say('This is an example of using convo.ask with a single callback.');
convo.ask('What is your favorite color?', (response) => {
convo.say('Cool, I like ' + response.text + ' too!');
convo.next();
});
});
});
controller.hears(['question'], ['direct_message', 'direct_mention'], (bot, message) => {
bot.createConversation(message, (error, convo) => {
convo.addMessage({ text: 'How wonderful.' }, 'yes_thread');
convo.addMessage({ text: 'Cheese! It is not for everyone.', action: 'stop' }, 'no_thread');
convo.addMessage({ text: 'Sorry I did not understand. Say `yes` or `no`', action: 'default' }, 'bad_response');
convo.ask('Do you like cheese?', [{
pattern: bot.utterances.yes,
callback: (response) => {
convo.gotoThread('yes_thread');
},
}, {
pattern: bot.utterances.no,
callback: (response) => {
convo.gotoThread('no_thread');
},
}, {
default: true,
callback: (response) => {
convo.gotoThread('bad_response');
},
}]);
convo.activate();
convo.on('end', () => {
if (convo.successful()) {
bot.reply(message, 'Let us eat some!');
}
});
});
});
};마무리
원래 봇을 통해 의도했던 ChatOps는 아직 시작하지 못했지만, 회사 행정에 도움 되는 기능부터 하나씩 스킬을 늘려가고 있습니다. 다음번에는 인터랙티브 메시지를 만드는 방법을 소개하도록 하겠습니다.
크로키의 스택 - REST API
30 May 2018
크로키가 클라이언트-서버 아키텍처를 가진 첫 번째 서비스 개발을 시작한 것은 2012년이었습니다. 클라이언트에서 서버와 통신할 방법이 필요했는데 당시의 대세는 REST API였습니다. 저도 거기에 공감했기 때문에 REST API를 만들어 클라이언트를 구현했습니다. 그 후로 모든 서비스는 기본적으로 REST API로 클라이언트와 서버가 통신하고 있습니다.
다만 여기서 말하는 REST API는 REST API라는 것에 대한 일반적인 인식 - 리소스 URI 명명법 및 HTTP 상태 코드 - 을 따른 API를 말하는 것으로, Roy Fielding이 얘기하는 REST 아키텍처와는 거리가 있습니다. Stateless 조건을 만족하는 대신 쿠키를 사용하고 있고, HATEOAS는 지금도 어떻게 사용하면 좋을지 감을 잡지 못하고 있습니다. Accept 헤더도 인식하지 않고 무조건 JSON을 가정하고 있습니다.
지금도 REST 스타일로 리소스 URI를 명명하는 것은 옳다고 생각하고, 웹 서비스의 각 페이지 주소는 최대한 REST 스타일로 이름 짓고 있습니다. 다만 API를 REST API로 하는 것이 맞는지는 계속 의문을 품고 있습니다. 다음은 수년간 서비스를 개발하면서 REST API 스타일이 적합하지 않는다고 생각한 예를 적어보겠습니다.
HTTP 동사로 처리하기 어려운 API
가장 처음에 맞닥뜨린 고민은 로그인, 로그아웃 API였습니다.
HTTP 동사에 딱 맞지 않는 경우 적당한 리소스 뒤에 동사를 붙이는 것으로 처리하는 경우를 많이 봤습니다.
예를 들어 로그인은 /users/me/login과 같이 처리하는 것이죠.
그런데 저는 동사를 피해야 한다고 하면서 마지막에 동사가 있는 것이 맘에 들지 않았습니다.
로그인/로그아웃의 경우 세션이라는 리소스를 다루는 것으로 간주하는 API 디자인도 봤습니다.
로그인 = POST /sessions, 로그아웃 = DELETE /sessions와 같이 대응시키는 것입니다.
하지만 너무 어색하게 느껴졌고, 이런 식으로 처리하기 어려운 예도 많았습니다.
그래서 이런 경우는 REST API가 아닌 API를 만들고 문서도 다르게 기술했습니다.
- REST API:
GET /users,POST /events - non-REST API:
/login (POST)
다음은 non-REST API로 만들었던 API들의 예입니다.
- 로그인:
/login - 사용자 A가 B에게 팀에 가입 요청(join_request)을 한 후 B가 해당 요청을 승인/거절:
/acceptJoinRequest,/ignoreJoinRequest - 특정 경기에 참여:
/joinMatch - 서비스 계정과 페이스북 계정의 연결/연결 끊기:
/linkWithFacebook,/unlinkWithFacebook
여러 리소스를 한 번에 가져오기
몇 개의 리소스에서 데이터를 한 번에 가져오고 싶은 경우에 API를 정의하기 어려웠습니다.
예를 들어 지그재그에서 사용자가 담아둔 상품의 가격을 갱신하기 위해서 서버에 데이터를 요청하는데 REST API로는 기술하기가 어려웠습니다.
굳이 하자면 GET /products/1,6,29,35/price 같은 형태를 생각해볼 수 있지만, 상품이 많은 경우 URL 길이의 제한에 걸릴 수 있습니다.
결국, 이런 경우 RPC 스타일로 API를 정의했습니다. /getProductPrices
요청자마다 원하는 데이터가 다른 경우
같은 리소스지만 모든 데이터가 필요하지 않은 경우 네트워크 사용량을 줄이기 위해 특정 필드만 반환하도록 fields 인자를 지정하는 REST API를 종종 보셨을 것입니다.
저의 경우 네트워크 사용량은 무시해서 fields 인자를 사용하지는 않았지만, 일부 필드는 추가적인 DB 접근이 필요한 경우가 있어서 필요한 경우만 요청하도록 하는 규칙을 정했었습니다. 예를 들어 이벤트 정보를 받을 때 이벤트가 열리는 장소와 참석자는 별도 테이블(Place, EventAttendance)에 있다 보니 다음과 같이 요청했습니다.
GET /events/123?add=attendances,place
같은 리소스지만 인자에 따라 처리 코드가 다른 경우
비슷한 상품 목록이지만 검색어 검색과 카테고리 검색의 코드가 다릅니다.
그런데 라우트는 GET /products 하나로 구성해야 합니다.
이런 경우가 있을 때마다 제대로 URL을 정한 것인지 고민이 됩니다.
특히 인자에 따라 결괏값이 달라야 하는 경우 같은 리소스가 맞나 싶을 때가 있습니다.
결정하기 어려운 이름
보통 리소스 목록은 /resources, 개별 리소스는 /resources/:id로 구성을 하지만,
가끔 리소스 목록에 후자를 쓰고 싶을 때가 있습니다.
상태(/resources/valid)나 검색(/resources/my-query) 같은 경우인데요,
페이지 URL이 REST 형태로 잘 구성되어 있다고 생각하는 GitHub에서도
https://github.com/nodejs/node/pulls/10000 같은 주소를 보면 쉽지 않다고 느낍니다.
결론
현재 크로키닷컴의 API는 REST API가 기본이지만 위에 적힌 이유로 마이크로서비스 간의 통신에는 Thrift를 사용해서 RPC 스타일의 API를 사용해 보고 있습니다. 또한, 최근에는 클라이언트-서버 간의 API도 통일하기 위해서 GrpahQL을 시도해보고 있습니다. 이에 대해서는 추후 다른 포스팅으로 설명하겠습니다.
젠킨스 작업을 정의하는 방식들
27 Feb 2018
오늘날의 소프트웨어 개발에 있어서 지속적 통합(continuous integration)은 필수라고 할 수 있습니다. 저도 당연히 동의하면서 오래전부터 도입하려고 했지만, 급한 일에 밀려 실제로 도입한 것은 지그재그 서비스를 오픈하고 나서도 2년이나 지난 작년 여름무렵입니다.
여러가지 고민한 끝에 CI에 젠킨스를 사용하기로 결정했습니다. 그런데 서비스에 적용하기 위해서 각종 문서를 찾아보는데 문서별로 작업을 정의하는 방식이 너무 달라서 굉장히 혼란스러웠습니다.
이번 글에서는 저와 같이 혼란을 겪으시는 분들을 위해 젠킨스의 작업 정의 방식들에 대해서 설명하려고 합니다.
UI를 통해 정의하기
젠킨스는 수많은 플러그인을 가지고 있습니다. 내가 젠킨스를 통해 하고 싶은 일을 수행해주는 플러그인을 찾았을 때 대부분은 UI에서 어떻게 설정하는지를 설명하고 있습니다. 또한 오래된 젠킨스 튜토리얼 문서들도 모두 이 방식으로 설명하고 있습니다.
예를 들어 다음은 코드 커버리지 리포트를 모아주는 Cobertura Plugin의 위키 페이지에 있는 설정 방법입니다.
- Install the cobertura plugin (via Manage Jenkins -> Manage Plugins)
- Configure your project’s build script to generate cobertura XML reports (See below for examples with Ant and Maven2)
- Enable the “Publish Cobertura Coverage Report” publisher
- Specify the directory where the coverage.xml report is generated.
- (Optional) Configure the coverage metric targets to reflect your goals.
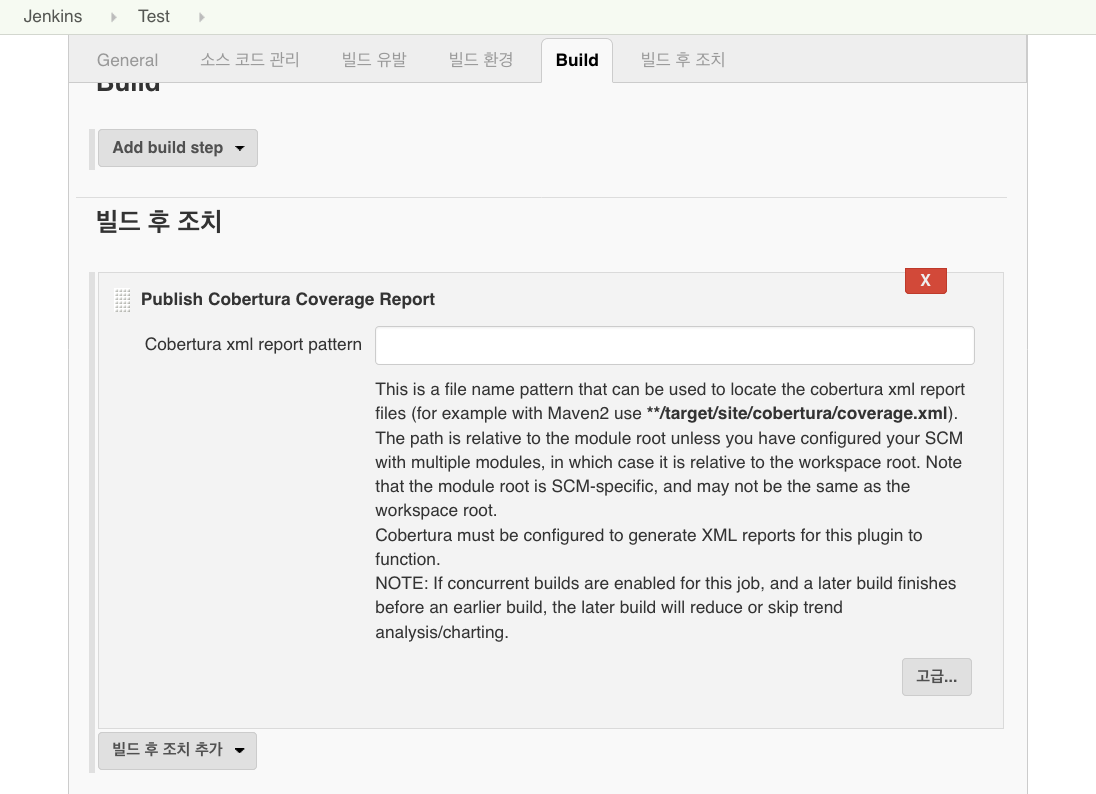
다음은 위 설명에 따라 Freestyle project를 생성한 후 Cobertura Plugin을 설정하는 화면입니다.
코드를 통해 정의하기
그런데 막상 젠킨스 공식 문서에서는 위와 같은 UI 화면을 전혀 찾아볼 수 없고, Jenkinsfile 라는 파일에 작업을 정의한다고 되어 있습니다.
작업을 코드로 정의해서 소스와 같이 관리하는 것이 바로 제가 원하는 것이였기 때문에, 이 방식을 적용하려고 했으나 아무리 찾아봐도 Freestyle project에서 Jenkinsfile을 연결하는 방법을 찾지 못했습니다. 한참을 삽질을 한 끝에 별도의 파이프라인 플러그인인을 설치해야 한다는 것을 알았습니다.
이는 2016년 4월에 릴리스된 Jenkins 2.0과 함께 공식적으로 소개된 기능입니다. 오래된 튜토리얼이나 위키 문서에 해당 내용이 없는게 당연하겠죠.
다음은 Pipeline project를 생성한 후 작업 파이프라인을 정의하는 예입니다.
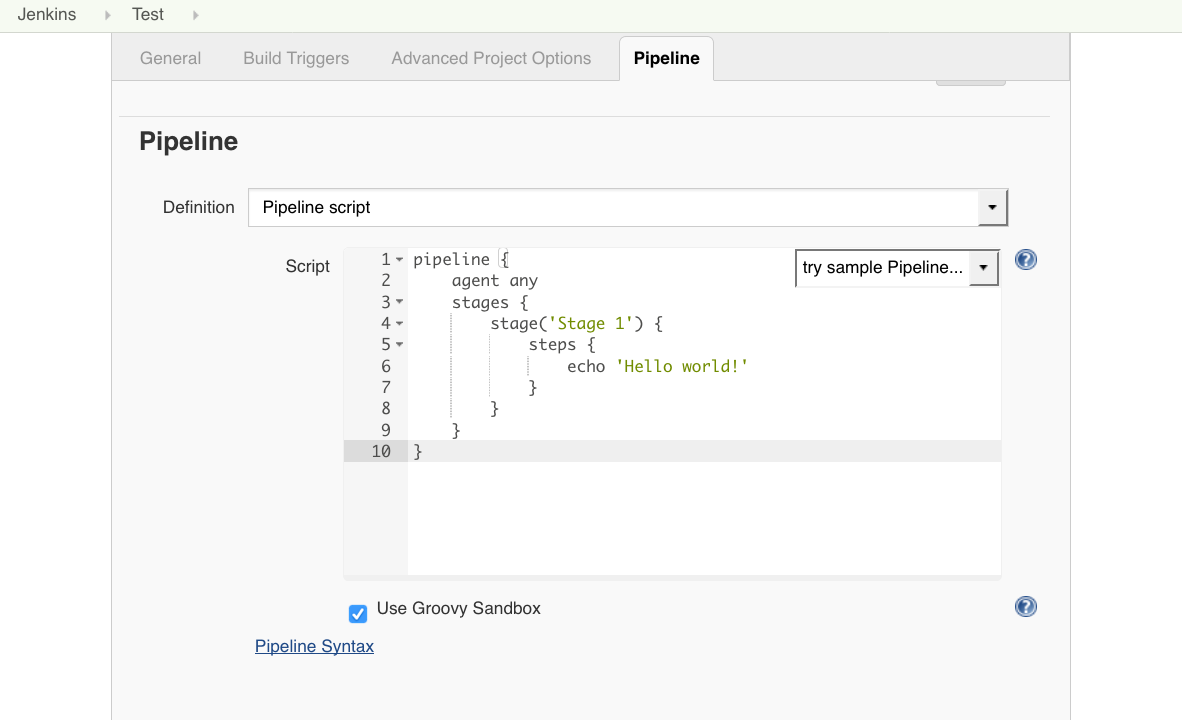
Declarative Pipeline? Scripted Pipeline?
그런데 파이프라인 문법 문서를 보면 두가지 스타일에 대한 얘기가 있습니다. 처음에는 Scripted 방식이였고 후에 Declarative 방식이 추가된 것으로 보입니다.
제가 원하는 기능을 파이프라인으로 정의하려고 하는데 생각한대로 동작하지 않아서 굉장히 혼란스러웠습니다. 문서는 Declarative 방식 위주로 되어 있는데, 그게 제가 원하는 동작을 정의하기에 맞지 않았던 것이 문제였습니다.
여러가지 시도 끝에 지금은 Scripted 방식으로 파이프라인을 정의해서 사용하고 있습니다.
Blue Ocean
제가 원하는 것은 GitHub 저장소와 연동되어 젠킨스 빌드가 이루어지는 것이였는데 이때 젠킨스의 새로운 UI 프로젝트인 Blue Ocean를 알게됐고 이를 통해 쉽게 GitHub 저장소와 연동되는 프로젝트를 만들 수 있었습니다.
그런데 이 Blue Ocean에는 파이프라인을 정의할 수 있는 UI가 포함되어 있습니다.
다음은 Blue Ocean에서 파이프라인을 정의하는 예입니다.
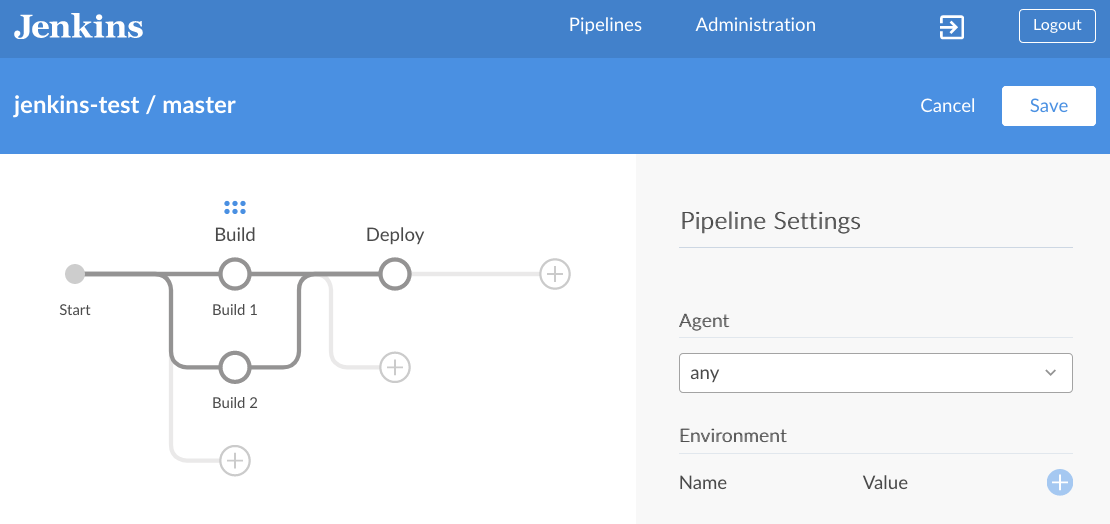
UI에서 정의한 내용은 다음과 같이 Declarative 방식의 Jenkinsfile로 만들어집니다.
pipeline {
agent any
stages {
stage('Build') {
parallel {
stage('Build 1') {
steps {
sh 'echo Build 1'
}
}
stage('Build 2') {
steps {
sh 'echo Build 2'
}
}
}
}
stage('Deploy') {
steps {
sh 'echo Deploy'
}
}
}
}결론
젠킨스가 오래된 프로젝트이고 기존 방식을 버리지 못하는 상황에서 새로운 방식을 추가하다보니 혼란스러운 점이 있었습니다.
새로운 프로젝트는 무조건 Jenkinsfile로 만들어서 소스에 추가한다고 생각하시는 것이 좋습니다. 초기 방식은 설정 파일이 소스와 별도로 존재해서 관리하기가 어렵습니다.
파이프라인 문법 중에서도 대부분의 경우 Declarative 방식을 사용하시는 것을 추천합니다. 초보를 위해 편집 UI도 제공하기 때문에 정의하기가 편리합니다.
이 글이 젠킨스 CI 구축에 도움이 되었으면 합니다.