크로키의 스택 - 마이크로서비스
15 Oct 2017
지그재그 서비스는 모놀리식 아키텍처(Monolithic Architecture)에서 마이크로서비스 아키텍처(Microservice Architecture)로 전환중에 있습니다. 이번 글에서는 그 과정을 설명하려고 합니다.
첫 서비스 구조
크로키는 2012년 중반에 첫 서비스 개발을 시작했습니다. 웹 서비스를 할 계획이 없었기 때문에 단순한 API 서버만 필요했고, 좀 더 성숙한 프레임워크(예. Rails)를 사용하는 대신 Node.js + Express 조합으로 서버를 구성하였습니다.
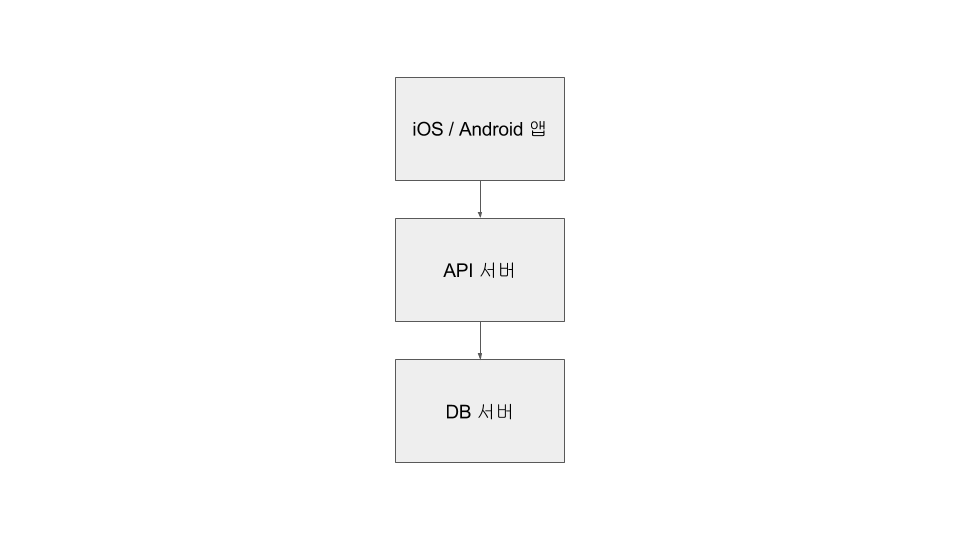
서비스가 알파 테스트 단계에 이르자 데이터를 살펴보고 간단한 조작을 할 수 있는 관리용 웹이 필요해졌습니다. 그래서 기존 서버에 관리용 API를 추가해서 관리용 웹을 만들었습니다.
복잡해지는 구조
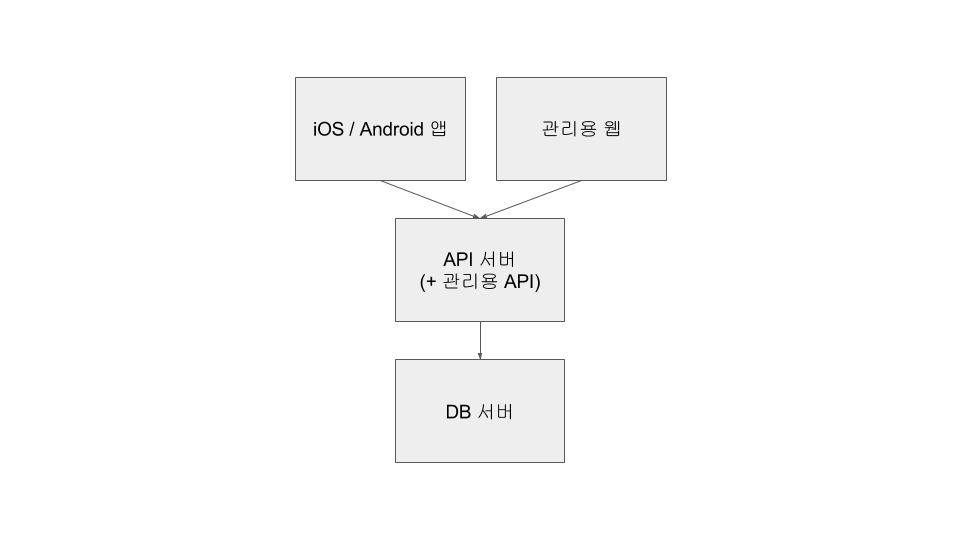
위의 구조는 2013년 중반에 작업한 외주 프로젝트에서도 그대로 사용했습니다. 그러나 2014년에 시작한 외주 프로젝트에서는 관리용 웹에 더 많은 기능이 필요했고, 서버 프로세스를 분리하기에 이르렀습니다. 코드상으로는 대부분의 코드를 공유하고 프로세스에 따라 라우트만 다르게 설정하는 구조였습니다.
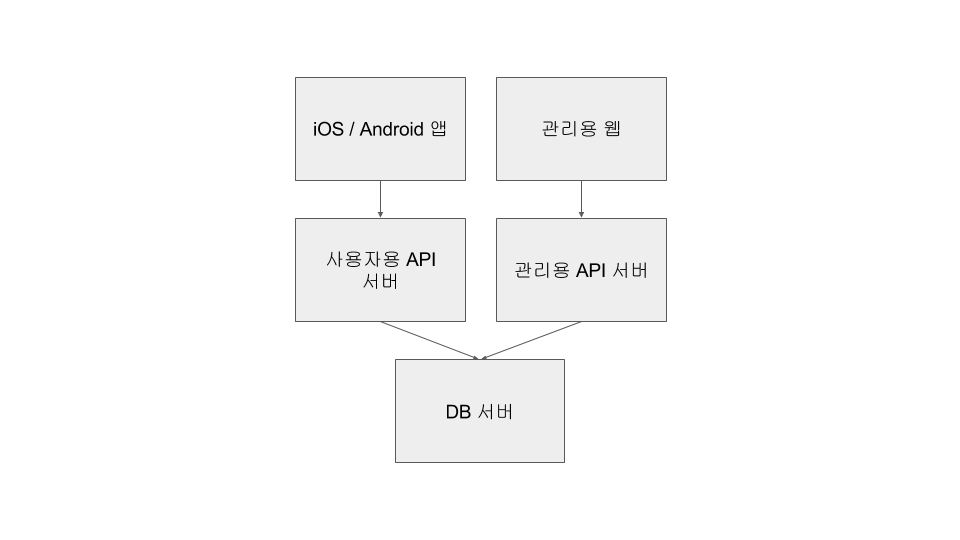
2015년 초에 지그재그 서비스 개발을 시작하였는데, 이전 프로젝트와 달리 사용자용 API는 굉장히 적은데 비해서, 관리용 API가 많아졌습니다. 거기에 업주용 웹이 필요해지면서 그에 따르는 API가 추가됐는데, 세 개의 API에 겹치는 부분이 없어서 모델 코드만 공유하고 나머지는 완전히 분리했습니다. 이 때 디렉토리는 서버와 클라이언트로 구분하지 않고, 타겟별로 구분을 하였습니다. (사용자용 API + 관리용 웹[API 서버, 웹 클라이언트] + 업주용 웹[API 서버, 웹 클라이언트] )
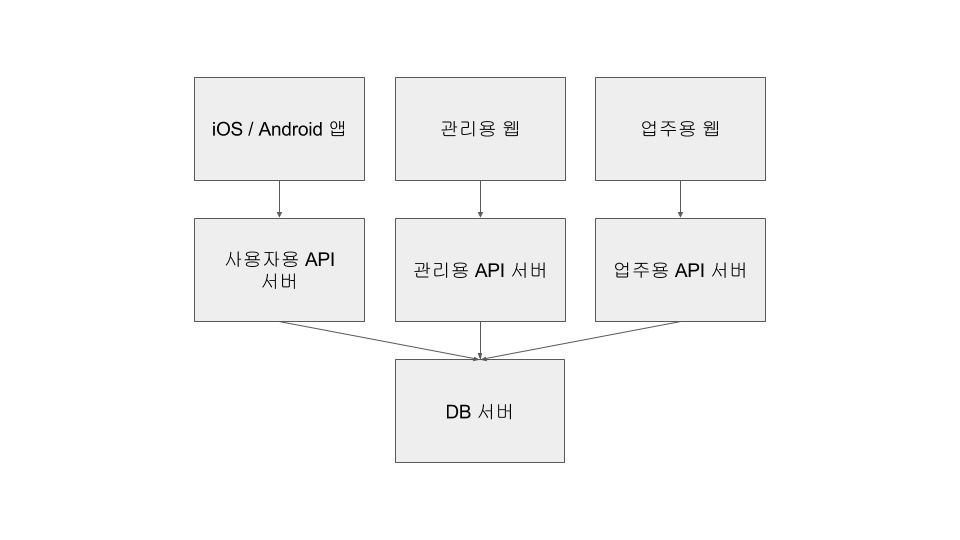
한때는 여기에 계약 관리용 웹이 별도로 존재하기도 했습니다.
마이크로서비스의 필요성
서비스가 점점 복잡해지면서 자연스럽게 마이크로서비스의 필요성이 느껴졌습니다. 개발팀이 크지 않기 떄문에 넷플릭스와 같은 진정한 의미의 마이크로서비스 까지는 아니지만, 적어도 연관된 기능을 한곳에 모아둘 필요성이 생겼습니다.
마이크로서비스로의 전환을 시작한 첫번째 직접적인 이유는 상품 검색 서버였습니다. 상품 검색에 AWS의 CloudSearch를 사용하고 있었는데, 한계를 느껴 Elasticsearch로의 전환을 생각하게 됐습니다. 그런데 상품 업로드는 관리용 서버에서 이루어지고 검색은 사용자용 API 서버에서 하기 때문에, 이를 한군데 모으면 변경하기 쉬워진다고 판단했습니다.
두번째는 로그관리였습니다. 로그를 MySQL 데이터베이스에 쌓고 있는데, Logstash, Apache Flume 같은 다른 시스템으로 전환을 하고 싶었습니다. 그러려면 로그를 추가하고, 사용하는 코드를 한군데로 모아야겠다고 생각했습니다. (하지만 로그 시스템은 여전히 못 바꾸고 있습니다;;)
마이크로서비스로의 전환 과정
2016년 8월에 전환 작업을 시작해서, 상품 서비스, 쇼핑몰 서비스, 사용자 서비스, 상품 검색 서비스 순으로 코드 분리를 시작합니다. 모든 기능을 한번에 이동하기 보다는 새로 추가되는 기능 위주로 조금씩 작업했습니다.
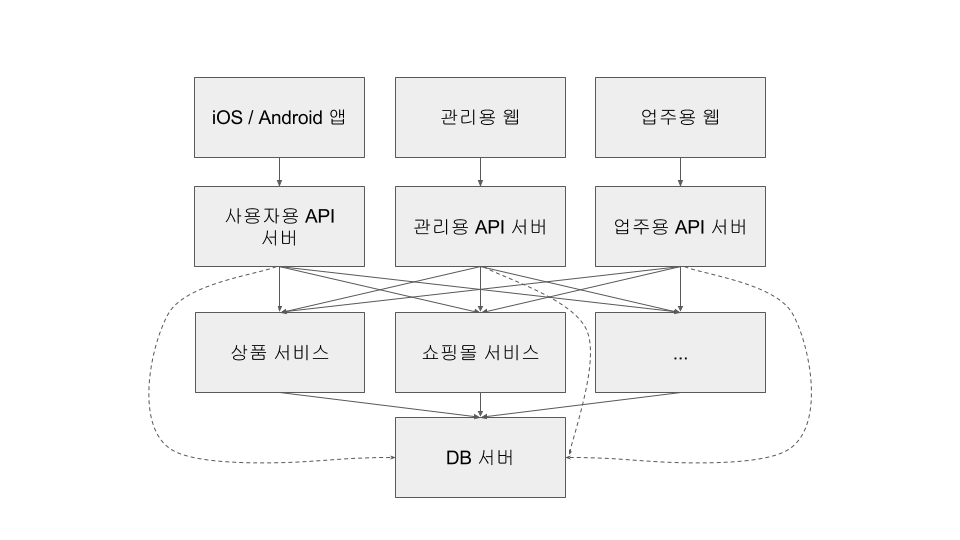
2017년 초에 새로 생긴 서비스에 대해서는 DB 서버도 분리(별도 RDS 인스턴스)했고, 8월에는 기존 데이테베이스도 거의 분리했습니다.
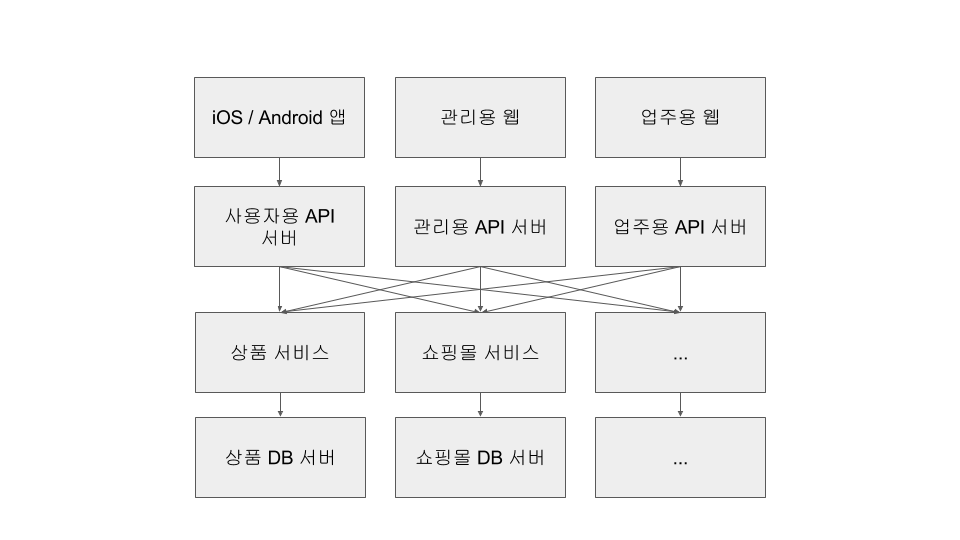
현재의 상태
전환을 시작한지 1년이 넘었지만 아직도 모든 코드와 데이터가 분리되지 않았습니다. 특히 주기적으로 실행하는 몇몇 작업은 여러 서비스의 데이터를 많이 참조해야 해서 마이크로서비스를 거치지 않고 데이터베이스에 직접 접근하고 있습니다.
그래도 마이크로서비스를 사용할 수 있는 구조가 잡힌 덕분에 최근에 작업하고 있는 BM 관련 기능은 별도의 마이크로서비스로 만들면서, 기존 서비스와 다르게 DynamoDB와 Lambda를 사용하도록 작업을 할 수 있었습니다.
현재의 구성을 용어로 표현하자면 프론트엔드를 위한 백엔드(backend for frontend, BFF) 패턴이라고 할 수 있을 것 같습니다. 이는 의도한 것이 아닌 마이크로서비스로의 전환 과정에서 자연스럽게 만들어졌습니다. 마이크로서비스를 직접 클라이언트에 노출하는 구성에 대해서도 생각해본 적이 있지만(예를 들어 상품 검색 기능), 여러 가지 이유로 적용하지는 않았습니다.
서비스간의 통신은 Apache Thrift를 사용하고 있습니다. 일반적으로 사용하는 REST를 사용하지 않은 이유는 다른 포스팅에서 다룰 생각입니다. 몇몇 상황에서는 비동기 이벤트의 필요성을 느껴 메시지 큐를 도입할 예정입니다.
모든 코드가 한 저장소에 존재하고 있고 배포는 따로 따로 할 수 있지만 실질적인 구현은 여러 마이크로서비스를 동시에 수정하는 경우가 많습니다. 현재는 진정으로 독립된 서비스라기 보다는 에러가 다른 서비스로 전파되는 것을 막고 원인을 찾을 때 범위를 좁히려는 목적이 강하다고 할 수 있습니다. 모든 서비스가 하나의 AWS 계정의 같은 VPC에 배포되고 있지만, 서비스별로 다른 계정을 만드는 것도 생각해보고 있습니다.
개별 서비스의 유닛 테스트는 잘 이루어지고 있지만, 서비스 단위를 넘어서는 통합 테스트는 아직 개개인의 경험에 의존하고 있습니다. 모니터링과 로그 수집도 더 발전할 여지가 많이 있습니다.
마무리하며
많은 곳에서 나오는 얘기이지만 서비스를 개발할 때 처음부터 마이크로서비스로 시작하는 것은 바보같은 일이라고 생각합니다. 어느 정도 기능이 갖춰지고 규모가 커진 이후에 고려해도 늦지 않습니다.
물론 한번 모놀리식으로 된 서비스를 마이크로서비스로 분리하는 것이 쉽지는 않습니다. 저희도 옮기면서 몇가지 실수로 데이터 손실이 발생하기도 했습니다.
하지만 아무도 사용하지 않는 좋은 구조의 서비스를 만드느니 어설프더라고 사용자가 원하는 서비스를 만드는 것이 더 중요합니다. 나중에라도 충분히 마이크로서비스로 전환하면서 기술 부채를 청산할 수 있습니다.
저희의 경험이 도움이 되셨으면 합니다.
webpack, TypeScript, Mithril을 사용하는 프로젝트 생성 튜토리얼
11 Apr 2017
클라이언트 JavaScript 개발 환경은 빠르게 변화하고 있습니다. 다양한 관련 기술 중 빌드 툴 쪽에서 최근 가장 주목 받는 것은 webpack이라고 할 수 있습니다.
webpack 전체는 굉장히 방대하기 때문에 한번에 이해하기가 쉽지 않습니다. 인터넷에 이미 잘 구성된 설정파일이 많긴 하지만, 기본적인 설정에 대해서 알아두면 많은 도움이 됩니다.
이번 글에서는 크로키에서 사용하는 TypeScript, Mithril 환경에 맞는 webpack 설정을 갖추는 과정을 단계별로 설명합니다.
기본이 되는 웹 페이지 생성 (3f7ac54)
우선 다른 툴/라이브러리/프레임워크를 배제한 기본 파일로 부터 시작합니다.
app/index.html
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>Sample App</title>
</head>
<body>
<script src='index.js'></script>
</body>
</html>app/index.js
console.log('Hello');app/index.html 파일을 브라우저로 열면 콘솔에 Hello가 출력됩니다.
npm 개발 환경 설정 (50fd3c0)
webpack, Mithril 라이브러리는 npm을 통해 사용하므로 npm 개발환경을 갖춰야 합니다.
package.json 파일을 생성하고 node_modules 디렉토리를 Git 무시 목록에 추가합니다.
package.json
{
"name": "setup-from-scratch"
}webpack을 통해 js 번들을 생성하기 (8978b0e)
webpack을 사용하면 원본 js 파일을 잘 묶어서 최종 js 파일을 만들어 내도록 할 수 있습니다.
우선 webpack을 설치합니다.
$ npm install --save-dev webpackapp/index.js 파일을 진입점으로 하는 묶음 js 파일 dist/main.js를 만들어내는 webpack 설정은 다음과 같습니다.
webpack.config.js
const path = require('path');
module.exports = {
context: path.resolve(__dirname, 'app'),
entry: './index',
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].js'
}
};webpack을 실행하면 최종 js 파일이 만들어지는 것을 볼 수 있습니다.
$ ./node_modules/.bin/webpack
Hash: d063a108d2635900dd0a
Version: webpack 2.3.3
...
$ ls dist
main.js예제에서는 원본 js 파일이 하나뿐이라 묶으나 안 묶으나 큰 차이가 없지만, import나 require등의 구문을 사용하면 요구하는 js 파일의 내용이 모두 main.js에 포함되는 것을 확인할 수 있습니다.
html-webpack-plugin을 이용해서 HTML 파일을 생성하기 (3b037f7)
결과물이 동작하려면 HTML 파일도 있어야 합니다. 단순히 app/index.html을 dist/index.html로 복사하는 방법도 있지만,
html-webpack-plugin을 사용하면 HTML 파일을 적절히 생성해 줍니다.
우선 html-webpack-plugin을 설치합니다.
$ npm install --save-dev html-webpack-pluginwebpack.config.js에 html-webpack-plugin 설정을 추가합니다.
webpack.config.js
const path = require('path');
+const HtmlWebpackPlugin = require('html-webpack-plugin');
+
module.exports = {
context: path.resolve(__dirname, 'app'),
entry: './index',
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].js'
- }
+ },
+ plugins: [
+ new HtmlWebpackPlugin({
+ template: 'index.html'
+ })
+ ]
};
html-webpack-plugin을 사용하면 최종 js 파일이 자동으로 HTML에 추가됩니다. 원본에서 이를 제거합니다.
app/index.html
<body>
- <script src='index.js'></script>
</body>
다시 webpack을 실행하면 dist/index.html 파일이 생성된 것을 볼 수 있습니다.
이 파일을 브라우저로 열면 이전과 마찬가지로 콘솔에 Hello가 출력됩니다.
webpack-dev-server 사용하기 (71e7af3)
파일을 수정할 때마다 webpack을 실행하는 것을 비효율적입니다. 한번 실행해놓고 파일을 수정하면 자동으로 브라우저에 반영되면 좋을 것 같습니다. 이럴 때 사용하는 것이 webpack-dev-server입니다.
webpack-dev-server를 설치하고 실행하면 파일을 수정할 때마다 브라우저가 릴로드됩니다. (–open 옵션을 주면 브라우저가 자동으로 실행됩니다.)
$ npm install --save-dev webpack-dev-server
$ ./node_modules/.bin/webpack-dev-server --openwebpack / webpack-dev-server를 실행할 때 경로를 써주는 것이 귀찮을 경우 npm 스크립트를 활용하면 편리합니다.
package.json
"devDependencies": {
"html-webpack-plugin": "^2.28.0",
"webpack": "^2.3.3",
"webpack-dev-server": "^2.4.2"
+ },
+ "scripts": {
+ "build": "webpack",
+ "start": "webpack-dev-server --open"
}
}
위와 같이 추가해주면 다음부터는 다음과 같이 실행할 수 있습니다.
$ npm start # 개발시
$ npm run bild # 배포 파일 생성시TypeScript 설정하기 (5bb9d39)
TypeScript를 사용하도록 설정하는 것은 webpack & TypeScript 문서를 참고하면 쉽게 할 수 있습니다. TypeScript 지원을 위한 loader가 두가지가 있는데 여기서는 awesome-typescript-loader를 사용합니다.
$ npm install --save-dev typescript awesome-typescript-loaderwebpack.config.js
path: path.resolve(__dirname, 'dist'),
filename: '[name].js'
},
+ module: {
+ rules: [
+ {
+ test: /\.tsx?$/,
+ loader: 'awesome-typescript-loader',
+ exclude: /node_modules/
+ }
+ ]
+ },
+ resolve: {
+ extensions: ['.js', '.ts', '.tsx']
+ },
plugins: [
new HtmlWebpackPlugin({
template: 'index.html'
원본 js 파일의 확장자를 ts로 변경하고 webpack을 실행하면 awesome-typescript-loader 에 의해서 js로 변경되어 최종 js로 합쳐집니다.
Mithril 설정하기 (d24f1ac)
사전작업이 끝났으니 이제 사용하려는 프레임워크를 추가하고 본격적인 코드를 작성해 보겠습니다.
최종 결과물에 포함될 프레임워크는 일반 의존 모듈로 추가하고, TypeScript를 위한 타입 정의 파일은 개발 의존 모듈로 추가합니다.
$ npm install --save mithril
$ npm install --save-dev @types/mithrilindex.html에 프레임워크가 렌더링할 타겟을 추가하고, 간단한 Mithril 코드를 작성해봅니다.
app/index.html
<body>
+ <div id='app'></div>
</body>
app/index.ts
import * as m from 'mithril';
class App implements m.ClassComponent<{}> {
view() {
return m('div', 'Hello Mithril');
}
}
m.mount(document.getElementById('app'), App);JSX 설정하기 (a106af0)
Mithril도 React에서 나온 JSX 문법을 사용할 수 있습니다. 이를 설정해봅니다. (저는 JSX를 선호하는데 Mithril 사용자들은 m() 형태를 더 선호하는 것으로 보입니다. https://github.com/lhorie/mithril.js/issues/1619)
TypeScript의 JSX 지원 기능을 사용하고, factory 함수를 Mithril에 맞게 설정하면 됩니다.
tsconfig.json
{
"compilerOptions": {
"jsx": "react",
"jsxFactory": "m"
}
}이제 JSX 문법을 사용할 수 있습니다. 다만 확장자를 tsx로 변경해야 합니다.
app/index.tsx
class App implements m.ClassComponent<{}> {
view() {
- return m('div', 'Hello Mithril');
+ return <div>Hello Mithril with JSX</div>;
}
}
CSS 추가하기 (53518ea)
이제 웹 페이지에 스타일을 적용해보겠습니다. 이는 css-loader와 style-loader를 사용해서 이루어집니다. 모듈을 설치하고 css 파일에 대해서 두 loader를 사용하도록 설정합니다.
$ npm install --save-dev css-loader style-loaderwebpack.config.js
test: /\.tsx?$/,
loader: 'awesome-typescript-loader',
exclude: /node_modules/
+ },
+ {
+ test: /\.css$/,
+ loader: ['style-loader', 'css-loader']
}
]
이제 스타일을 추가해봅니다.
app/index.css
.message {
font-size: 20px;
color: magenta;
}app/index.tsx
import * as m from 'mithril';
+import './index.css';
+
class App implements m.ClassComponent<{}> {
view() {
- return <div>Hello Mithril with JSX</div>;
+ return <div class='message'>Hello Mithril with JSX</div>;
}
}
웹 페이지의 텍스트에 크기와 색상이 적용된 것을 볼 수 있습니다.
지역 범위의 CSS 적용하기 (6105a82)
컴포넌트별로 나누어서 개발을 하는 경우 CSS도 각 컴포넌트별로 가지는 것이 편리합니다. 이 경우 다른 컴포넌트와 클래스 이름이 겹쳐서 컴포넌트 조합후 전체 스타일이 엉망이 될 가능성이 있습니다. 이를 해결하기 위해서 BEM과 같은 네이밍 컨벤션을 사용하기도 하고, 스타일을 HTML 원소 인라인으로 포함시키기도 합니다.
저는 css-loader의 지역 범위 기능을 선호합니다. 이를 사용하면 같은 클래스 이름을 사용해도 최종 결과물에서는 겹치지 않는 이름으로 변경됩니다. 대신 코드에서 이렇게 임의로 생성한 이름을 CSS 클래스명으로 설정하는 작업이 필요합니다.
지역 범위를 사용하려면 CSS 파일에 :local을 붙여줍니다.
app/index.css
-.message {
+:local .message {
font-size: 20px;
이렇게 하면 index.css가 다음과 같은 구조체를 내보냅니다.
module.exports = {
"message": "Ag7q-vI0hGDj8L_qsNLr7"
}이 구조체를 사용해서 HTML 원소에 적절한 클래스명을 설정해줍니다. 다만 TypeScript가 CSS 파일이 내보내는 구조체를 인식하지 못하기 때문에 타입 정의 파일을 만들어 줘야 컴파일이 됩니다.
app/index.d.ts
declare module '*.css' {
const styles: { [key: string]: string };
export = styles;
}app/index.tsx
+/// <reference path='index.d.ts'/>
+
import * as m from 'mithril';
-import './index.css';
+import styles = require('./index.css');
class App implements m.ClassComponent<{}> {
view() {
- return <div class='message'>Hello Mithril with JSX</div>;
+ return <div class={styles.message}>Hello Mithril with JSX</div>;
}
}
다만 이렇게 하면 CSS의 클래스명에 대한 검증을 하지 못합니다. (styles.massage로 오타를 내도 알 수 없음) 이에 대한 타입 정의 파일을 만들어 주는 typed-css-modules 모듈은 있지만, webpack과 부드럽게 연동하는 방법은 찾지 못했습니다.
스타일을 별도 CSS 파일로 내보내기 (37a2741)
위와 같이 CSS를 작업한 경우 실행시간에 style 원소로 추가됩니다.
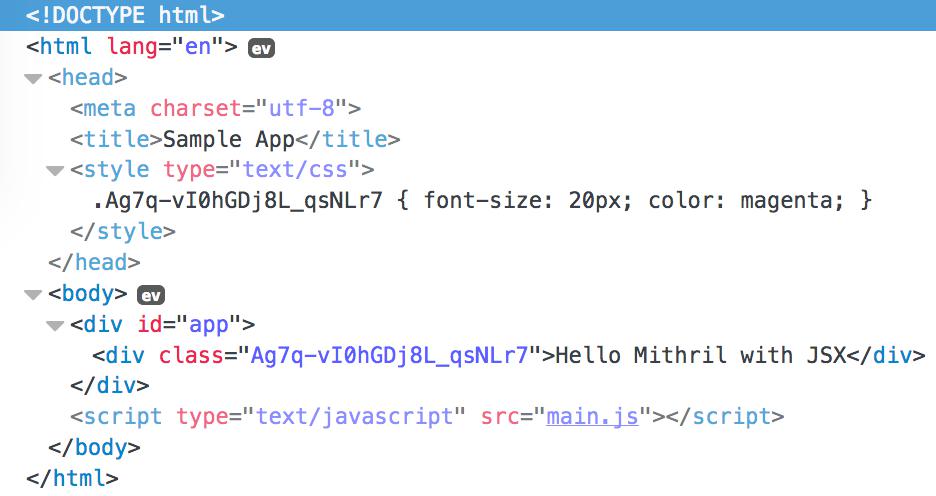
저는 이것보다는 별도의 CSS 파일로 내보내고 싶었습니다.
이는 extract-text-webpack-plugin을 사용해서 할 수 있습니다.
extract-text-webpack-plugin 모듈을 추가하고, 적절한 설정을 해주면 main.css 파일이 만들어집니다.
이 extract-text-webpack-plugin 사용시 style-loader는 필요하지 않습니다.
$ npm install --save-dev extract-text-webpack-pluginwebpack.config.js
const path = require('path');
+const ExtractTextPlugin = require('extract-text-webpack-plugin');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
...
},
{
test: /\.css$/,
- loader: ['style-loader', 'css-loader']
+ loader: ExtractTextPlugin.extract('css-loader')
}
]
},
...
plugins: [
new HtmlWebpackPlugin({
template: 'index.html'
+ }),
+ new ExtractTextPlugin({
+ filename: '[name].css'
})
]
마무리 (f596154)
마지막으로 배포를 위한 코드 최적화 버전을 생성합니다.
webpack은 이를 위한 간단한 옵션을 제공합니다. -p 만 붙여주면 js 파일과 css 파일이 최소화됩니다.
package.json
"scripts": {
- "build": "webpack",
+ "build": "webpack -p",
"start": "webpack-dev-server --open"
}
webpack은 여기서 다루지 못한 많은 기능을 가지고 있습니다. 예를 들어
- 원할한 캐싱을 위해 내용에 따라 파일명을 다르게 생성하는 기능
- 외부 라이브러리를 vendor.js 등의 파일로 분리
- SASS등의 CSS 전처리기 사용
- 이미지, 글꼴 파일 처리
- Hot Module Replacement
등이 있습니다. 이런 부분들은 차후 기회가 되면 다른 글로 소개하도록 하겠습니다.
크로키의 스택 - Mithril
07 Apr 2017
이번 글에서는 크로키가 사용하는 스택 중 클라이언트 JavaScript 프레임워크(client-side JavaScript framework)에 대해서 소개해볼까 합니다.
TD;DR) 크로키에서는 Backbone, Angular를 거쳐 현재는 Mithril이라는 프레임워크를 사용하고 있습니다.
크로키는 현재 지그재그라는 서비스에 주력하고 있지만, 지그재그가 첫 제품은 아닙니다. 창업 후 여러 제품을 만들었는데 모두 네이티브 모바일 앱이 기본이였고, 일반 사용자를 위한 웹 서비스는 없었습니다. 그렇다고 전혀 웹 어플리케이션을 개발하지 않는 것은 아니고, 크로키 내부 직원이나 한정된 외부 사용자를 위한 웹 어플리케이션은 꾸준히 개발해왔습니다.
2012년 초, 처음 개발하던 iOS 앱(쿠키단어장)은 Vanilla JS와 UIWebView로 시작했습니다. (1주일 정도 개발하다가 JavaScript에서 CoffeeScript로 전환했습니다.) 하지만 2주 정도 개발하다가 한계를 느껴 네이티브로 전환했습니다.
2012년 여름 개발을 시작한 두번째 제품(Teamable)은 모바일 웹 앱으로 시작했습니다. 그때 서버쪽에서 HTML 렌더링을 하기 보다는 클라이언트에서 렌더링을 하는 구조로 가져가기로 했습니다. 각각의 장단점을 생각해보고 결정한 것이지만, 서버쪽에서 할 일을 클라이언트에 맡김으로써 서버 비용이 줄어든다는 생각이 컸던 것으로 기억합니다. (사실 몇명쓰지도 않는 서비스에서 아무 차이도 없지만)
이때 선택한 클라이언트 JavaScript 프레임워크는 Backbone이였습니다. (당시 0.9.2) 당시에도 Angular는 있었던 것 같은데, 제가 접하는 범위에서는 Backbone이 대세였습니다.
얼마 후 웹 앱이 아니라 모바일 앱을 만드는 방향으로 전환했고, 잠시 Apache Cordova(PhoneGap)을 시도해봤지만 결국은 네이티브 모바일 앱으로 전환했습니다. 하지만 그때까지 개발된 JavaScript 클라이언트 소스는 간이 관리 사이트에서 계속 사용됐습니다.
2013년 4월부터는 두번째 제품을 바탕으로 외주를 받은 세번째 제품의 개발을 시작했습니다. 여기에 한정된 외부 사용자를 위한 관리 사이트가 필요했고, 자연스럽게 Backbone을 사용했습니다. (그리고 Bootstrap을 사용하기 시작했습니다.)
이때부터 SPA에 대한 관점이 정리된 것 같습니다. 저희는 모바일 앱이 기본이다보니 서버쪽은 여기에 데이터를 제공하는 API 위주로 개발이 이뤄졌습니다. 그리고 SPA는 이 API를 동일하게 써서 개발할 수 있다는 장점이 있었습니다. SPA의 단점은 무시할 만 했습니다. (SEO - 로그인이 필요한 사이트로 검색 엔진 연동 자체가 의미 없음, 큰 파일 크기로 인한 로딩 속도 - 한정된 사용자에게는 별로 이슈 안 됨)
2014년이 되어 세번째 제품의 2014년 버전 개발에 들어갔습니다.
2013년 버전에서 Backbone으로 만든 관리 사이트가 점점 커지면서 소스 관리에 한계를 느꼈고(파일도 단순히 concat으로 합치고 있었습니다) 다른 프레임워크를 찾게 되었고 그때 선택한 것이 Angular였습니다. (당시 1.2) Yeoman을 통해 Angular를 프레임워크로 쓰고, Grunt를 빌드 툴로 쓰는 프로젝트를 생성해 새로 관리 사이트를 만들었습니다.
기존 기능이 계속 유지됐으면 코드를 완전히 재작성하는게 쉽지 않았을 수도 있지만, 2013년 버전과 2014년 버전의 요구 사항이 많이 달랐기에 과감하게 처음부터 작성을 했습니다.
그렇게 2014년에는 Angular를 써서 원하는 결과물을 만들 수 있었습니다. 하지만 쓰면 쓸 수록 Angular는 저와 맞지 않는 다는 생각이 들었습니다. 보통 Angular에 속도에 많은 이슈가 있어서 React, Vue등으로 넘어가는 경우가 많은데, 저는 라이브러리/프레임워크의 복잡도가 문제였습니다. 저는 어떤 라이브러리/프레임워크를 사용할 때 내부 코드를 종종 살펴보는데 Angular는 쓸데없이 복잡하다는 생각이 들었습니다.
2014년 말, 2015년 초에는 React 얘기가 많이 나오기 시작하던 시기로 Angular와 React의 비교 글들이 많이 있었던 걸로 기억합니다. 그러던 와중에 Hacker News인가의 댓글로 Mithril이라는 프레임워크를 알게됐고, 소개글이 마음에 들었습니다. 다른 프레임워크에 비해서 속도가 빠르다는 얘기도 있었지만, 그 부분은 크게 문제가 되는 부분이 아니였고, 크기가 작다는 것이 마음에 들었습니다.
2015년 초에 시작한 지그재그 서비스의 내부 관리 사이트을 Mithril로 시작해서 그 후 작성한 모든 웹 어플리케이션은 Mithril을 사용하고 있습니다.
2017년 4월 현재도 Mithril을 사용하고 있고, 올해 1.0으로 올라가면서 구조도 안정화됐습니다. Mithril을 사용하면서 Grunt에서 gulp로 넘어갔다가 최근에는 webpack으로 전환했습니다. 언어는 여전히 CoffeeScript가 주요언어지만, TypeScript로의 전환을 시작했습니다.
최근에는 Vue가 꽤나 이슈가 되고 있는데 저는 계속 Mithril을 사용할 것 같습니다.
마지막으로 많은 프레임워크에 혼란을 겪으시는 분들을 위해 제가 생각하는 선택 기준을 말씀드리겠습니다.
- Angular: Spring 처럼 틀이 갖춰져 있어서, 잘 모르는 사람이 어느 정도 이상의 품질을 갖춘 제품을 만들고 싶을 때
- React: 좋은 구조를 가진 제품을 만들고 싶고, 빠르게 발전하는 트랜드를 따라갈 자신이 있을 때
- Vue: React와 비슷한 것을 원하지만 조금 더 안정된 것을 원할 때
- Mithril: 복잡한 기능 필요없고 가급적 Vanilla JS에 가깝게 코드를 작성하고 싶을 때